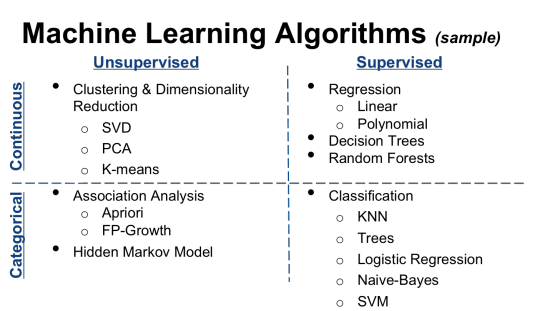
Classification : Machine Learning is used to label input data based on the training data provided. This labeling of data is called classification. Here, the record is classified into one of the possible groups by the algorithm. The output here is the class labels.
Consider the familiar email Spam Classification example. Here, initially, a set of spam emails are used to train the model and then, any new email that hits your inbox is classified as either spam or not-spam. This is a Classifier Model in Machine Learning.
There various classifier models in practice. The right classifier for a solution depends various factors. Following are few common classifier model and reasons to choose them:
- Boosting – often effective when a large amount of training data is available.
- Random trees – often very effective and can also perform regression.
- K-nearest neighbors – simplest thing you can do, often effective but slow and requires lots of memory.
- Neural networks – Slow to train but very fast to run, still optimal performer for letter recognition.
- SVM – Among the best with limited data, but losing against boosting or random trees only when large data sets are available.
Ref: An answer in Stackoverflow pointing to “OpenCV” book.
Prediction/Regression : Unlike Classification, regression is type of problem where algorithm finds a continuous number/value from the given input. A simple example would be – predict price of an house, given no.of rooms, area and location. Here, a training set of houses with known price are fed into the model. The algorithm comes up with an equation to apply on new inputs further. Another example is predicting the price of a stock, given various input features.
The output here is a continuous value of the target variable.