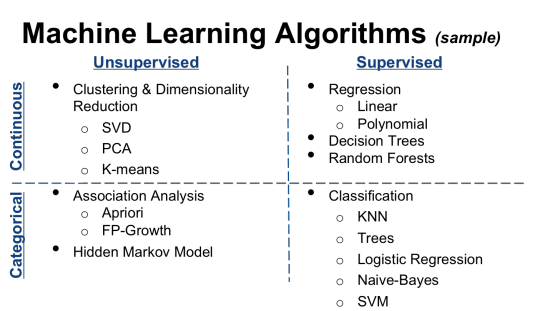
Unsupervised learning is the method of finding hidden pattern or classifications within data on its own. Unlike supervised learning, there are no labels or training data here. The data is clustered into groups by the algorithm using the similarity in data’s features. In most of the cases, we do not know the reason behind formation of clusters unless we analyse the features of data in each cluster.

Commonly used unsupervised algorithms are:
- Self Organizing maps
- k-means clustering
- Hierarchical clustering
- Hidden Markov Models
- Gaussian mixture models
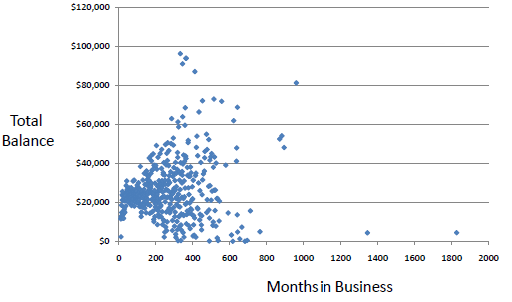
A good example would be clustering of fans/followers of a Facebook page or Twitter handle. The features would be the profile details of each user and clusters would have similar users grouped together.
Workflow Diagram Reference for my last two posts : machine-learning-who-s-the-boss
In next post, I will discuss about each of the algorithms of supervised and unsupervised categories briefly.