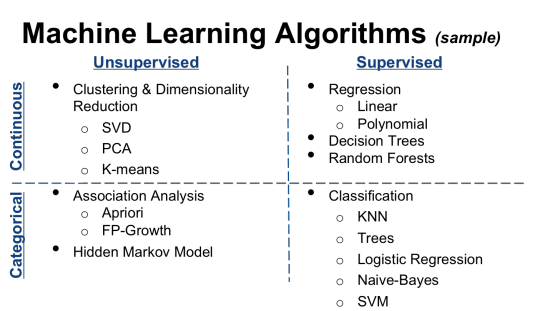
Three basic terms to be learnt in machine learning are:
Concept : A concept is what the machine learns in the process. In a classification task, it learns how to classify. This is concept.
Instances : Each row/record in training data set is an instance. It can be collection of 1 or more attributes.
Attributes : As explained above, attributes are each column/field in the data set. These are used by the algorithm to come up with the hypothesis from the data set.
Next post would be about Training and Test data. I would also be writing about topics I learn and exercise I practice in Coursera – Machine Learning course in parallel. 🙂 🙂